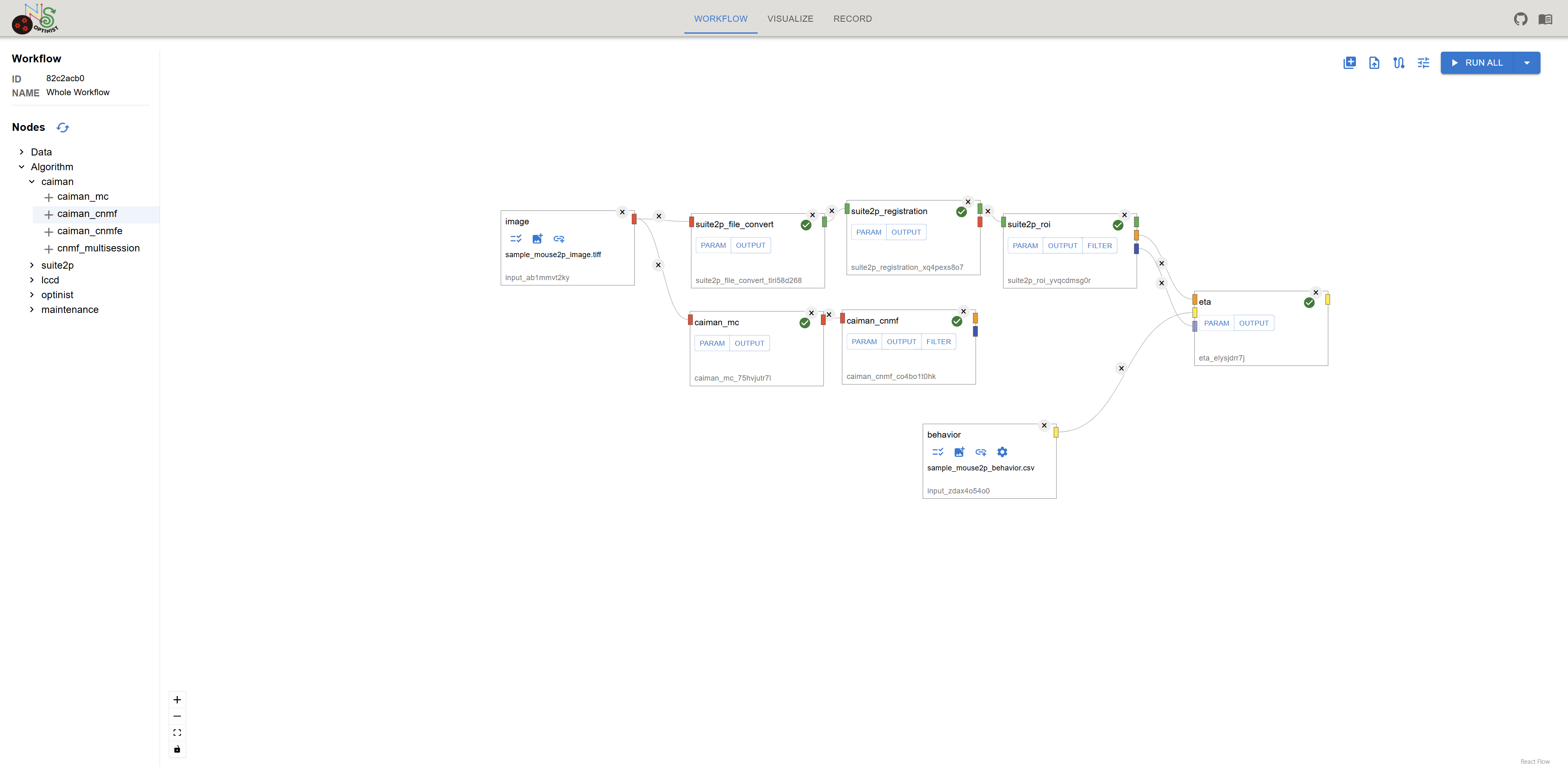
Workflow
OptiNiSt makes it easy to create analysis pipelines using the GUI.
In the workflow field, you can:
Select the data and the algorithms or analysis methods (node).
Connect these nodes to define the order of processing (workflow).
The analysis pipeline can be parallel or bifurcating.
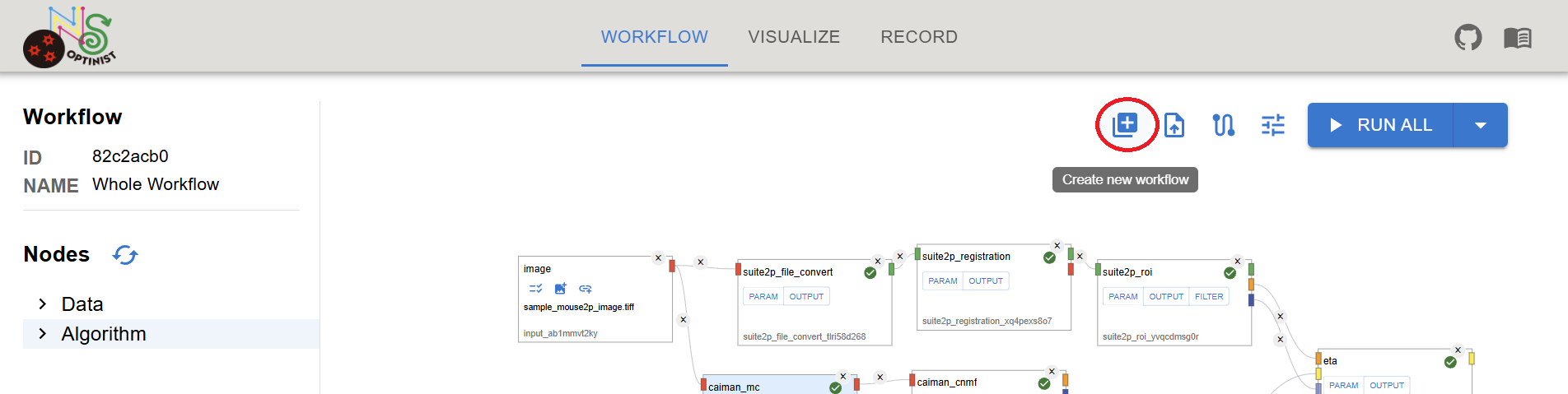
See Data Nodes for a description of which data types each node accepts. Data shape is displayed in the file select dialog. Please check data shape if you have unexpected results. If you replace the image file with the same file name, shape cannot be updated automatically. Please click reload icon besides the checkbox. See Algorithm Nodes for a description of each data processing and analysis node. You can create a new workflow by clicking the + button.
Caution By creating a new workflow, current workflow will be deleted. The records are kept if you have already RUN the workflow. You can reproduce the workflow from RECORD tab. See details here. Select or drag Data or Algorithm nodes from the treeview on the left.
Clicking the + button adds the analysis nodes to the Workflow field.
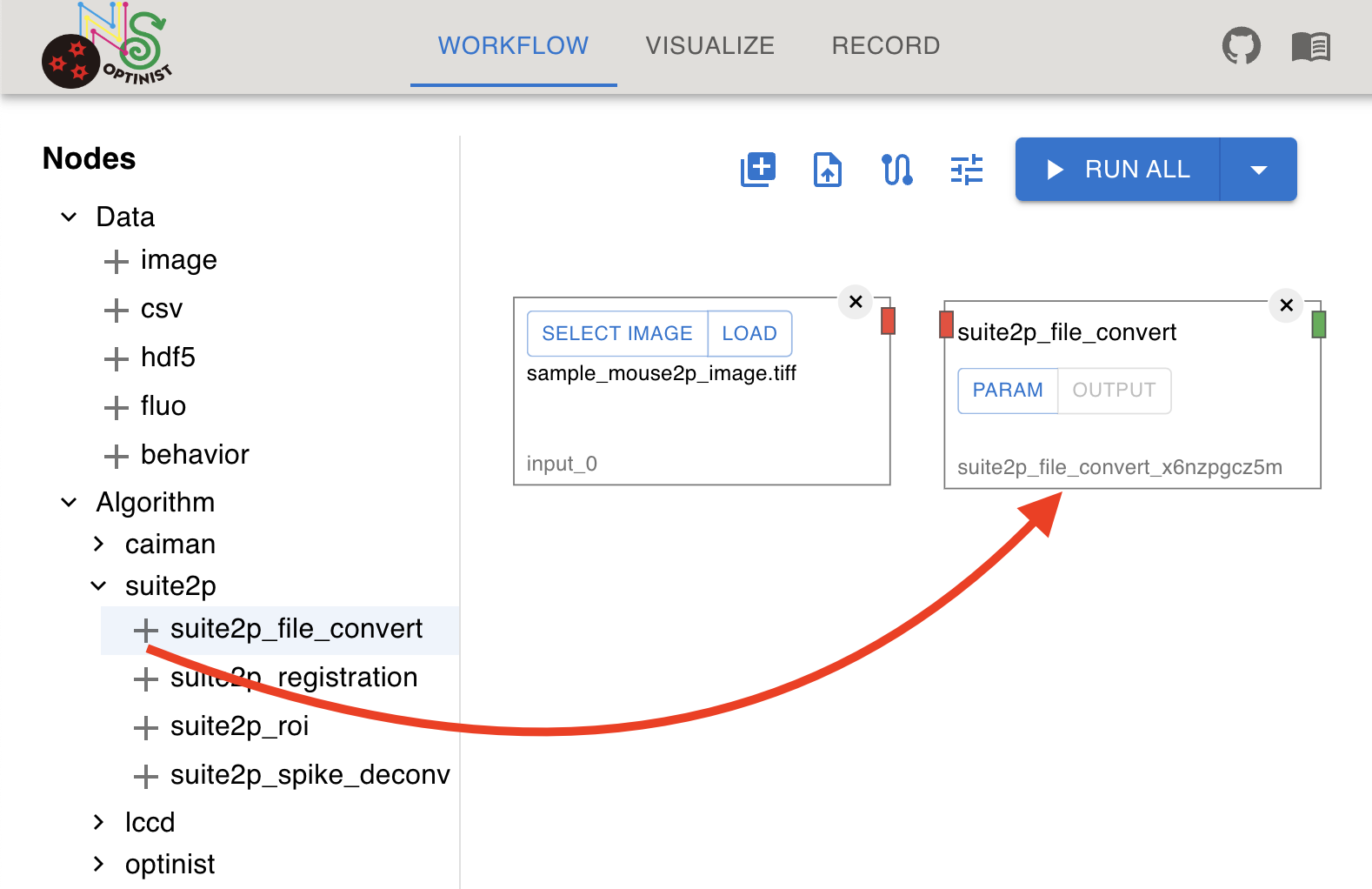
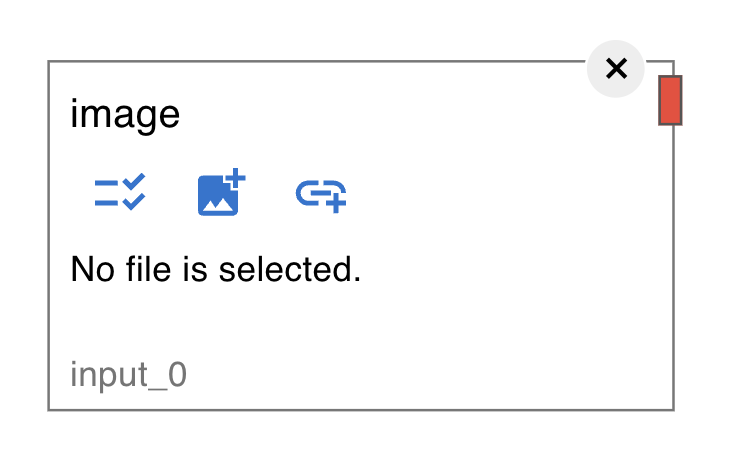
The left side of the window displays all available analysis methods. ROI detection tools (currently Suite2P, CaImAn and LCCD) are in the “Algorithm” category, and all other pre-installed analyses are in the “optinist” category. Image (TIFF) By default, an Image node is displayed. This node defines the path to the data to use.
To select the data, follow these steps: Click on the check list icon on the Image node. Select a file or a folder. Choosing a folder makes all the TIFF files in the shown sequence an input set of continuous frames. You can select files in
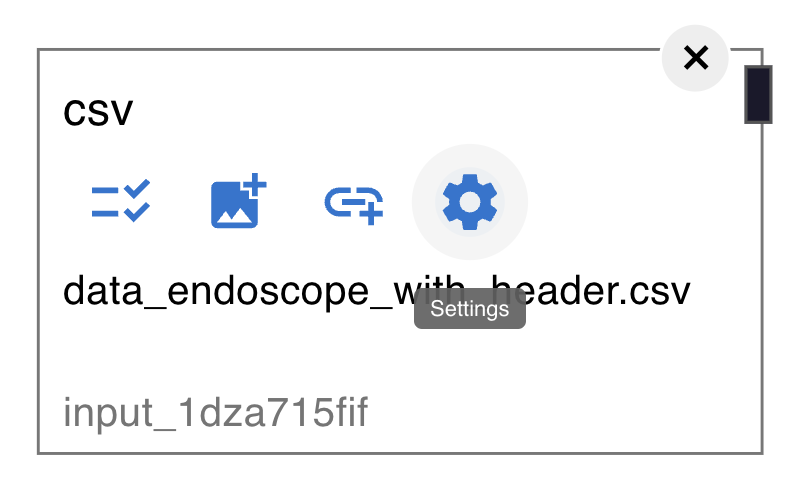
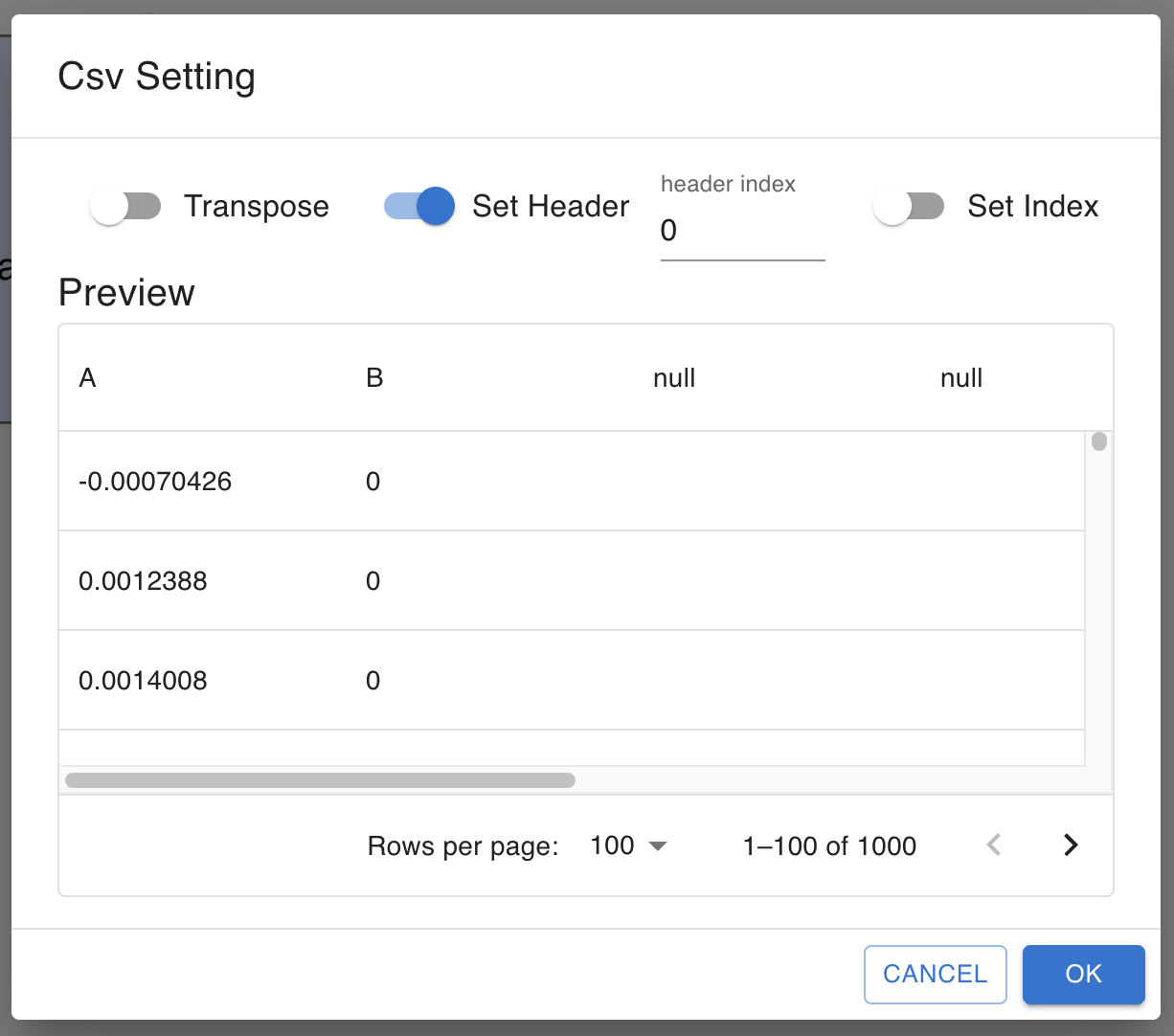
CSV, FLUO, BEHAVIOR These nodes are for csv data.
Once the file selected, you can preview and change settings for the data.
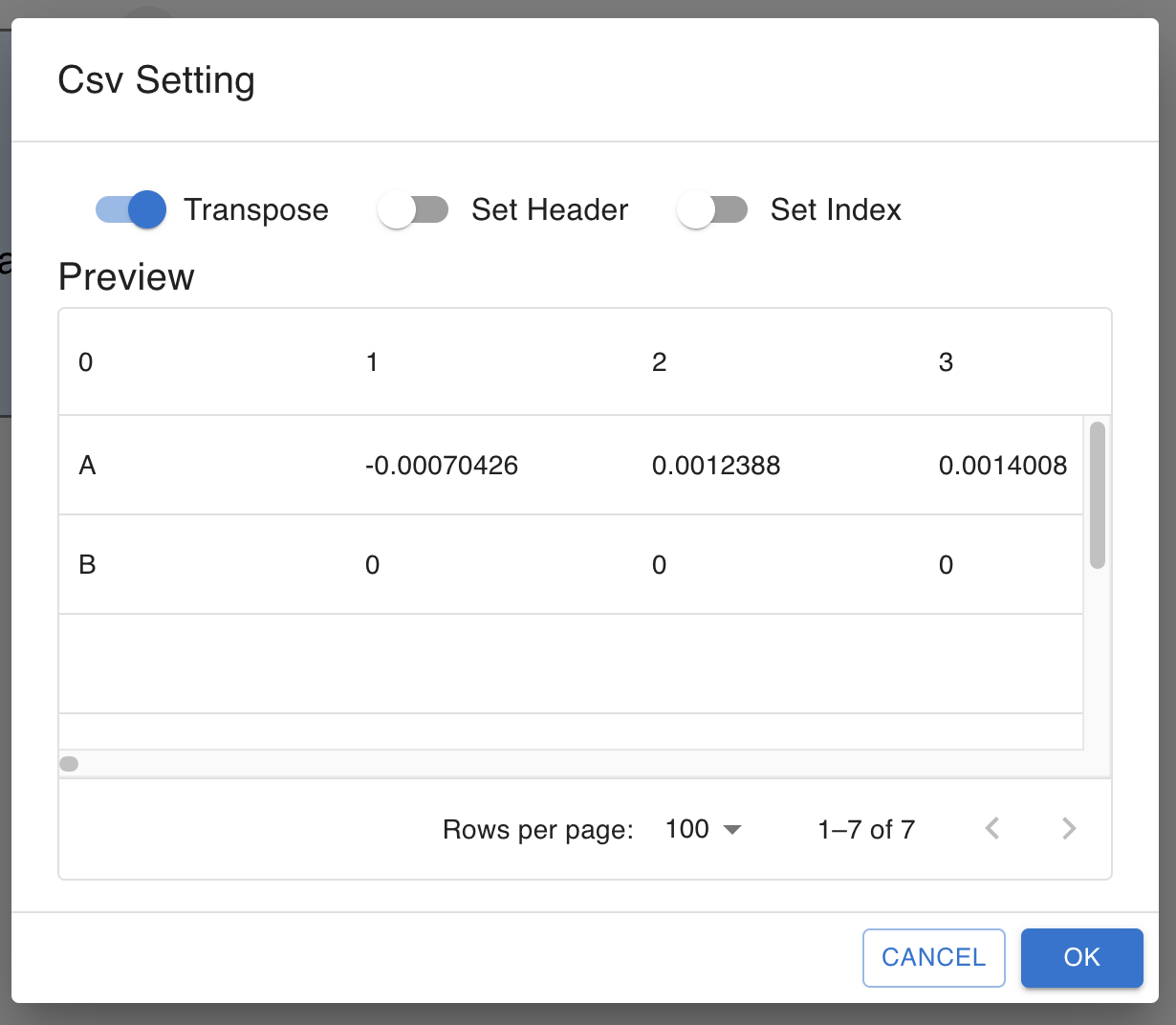
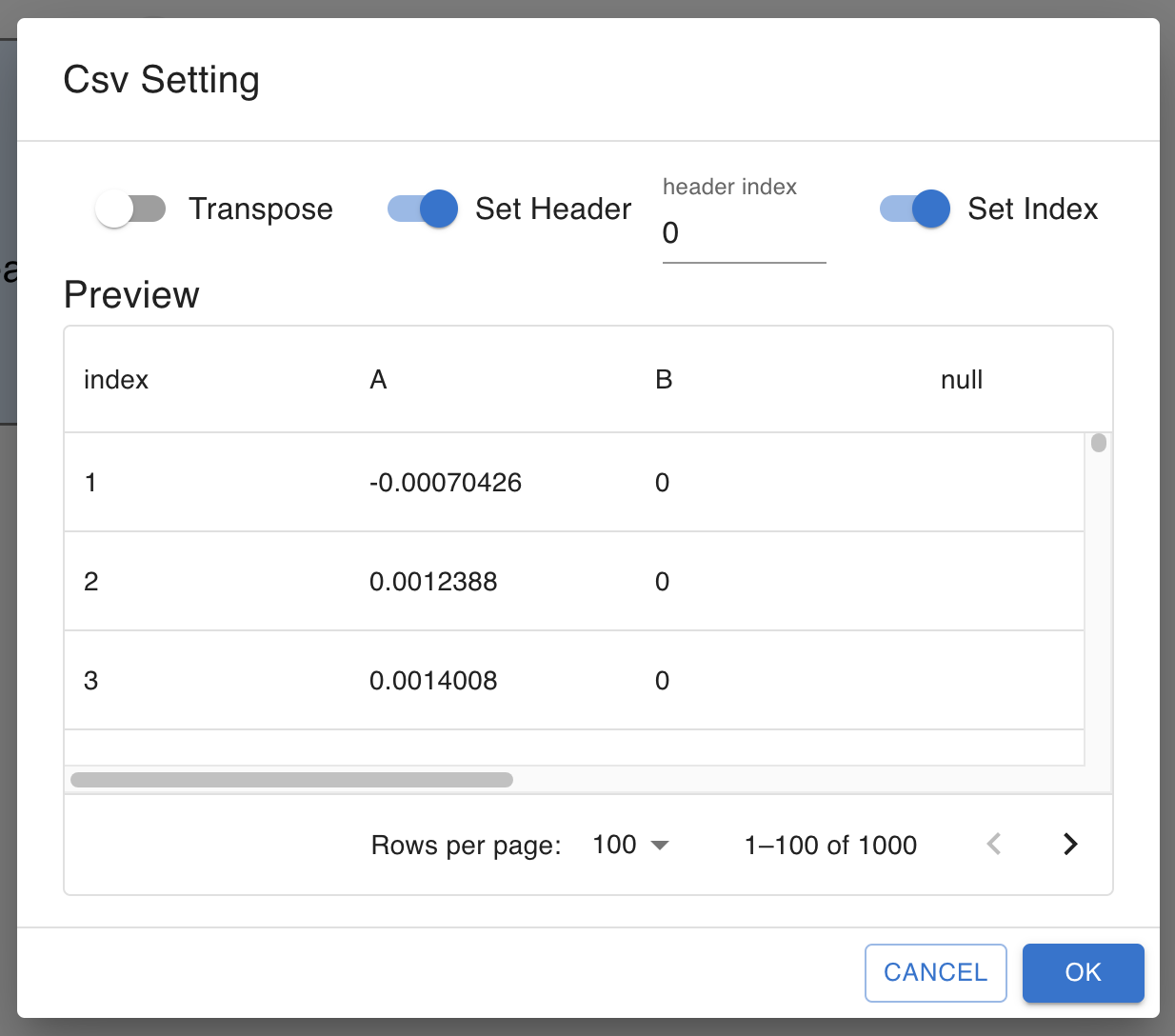
transpose You can use transposed the data as the input by checking this box.
ETA, CCA, correlation, cross_correlation, granger, GLM, LDA, and SVM assume the input neural data shape is frames x cells matrix.
Because the output of CaImAn and Suite2P on the pipeline is cell x frames, the default setting for neural data for these analyses is set to transpose. PCA and TSNE can be done in either direction depending on your purpose.
The function assumes their input to be samples x features. set_header If your CSV data has header, check this box.
Set the header index to your data’s header row. (first row is 0)
The data below the header row will be used as the data.
set_index You can add index column to the data by checking this box.
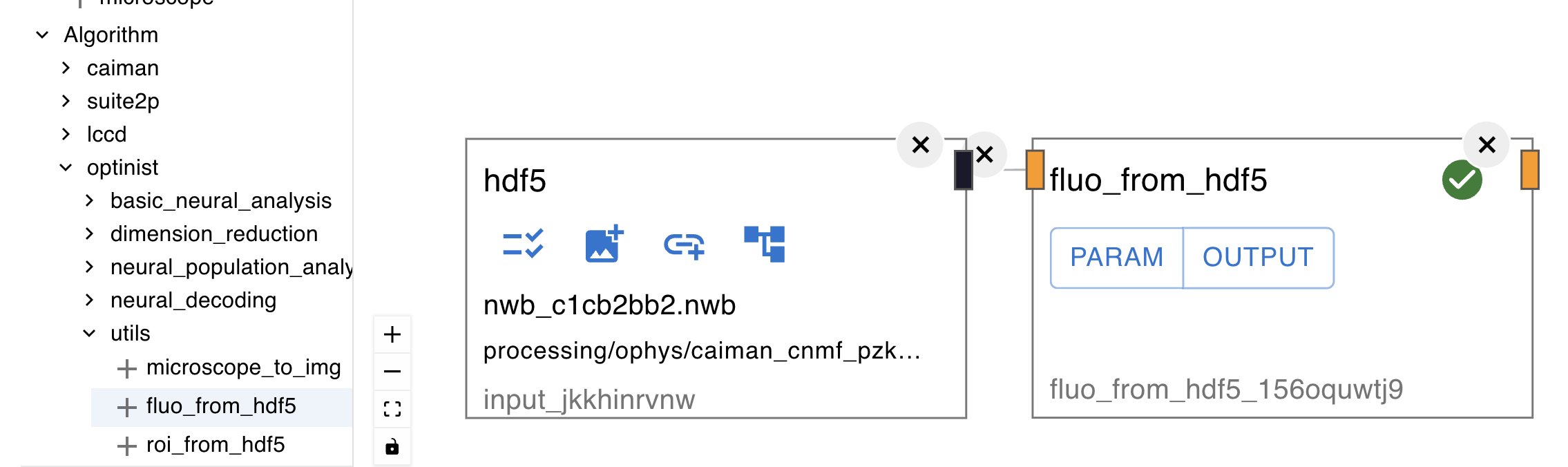
HDF5 This node accepts
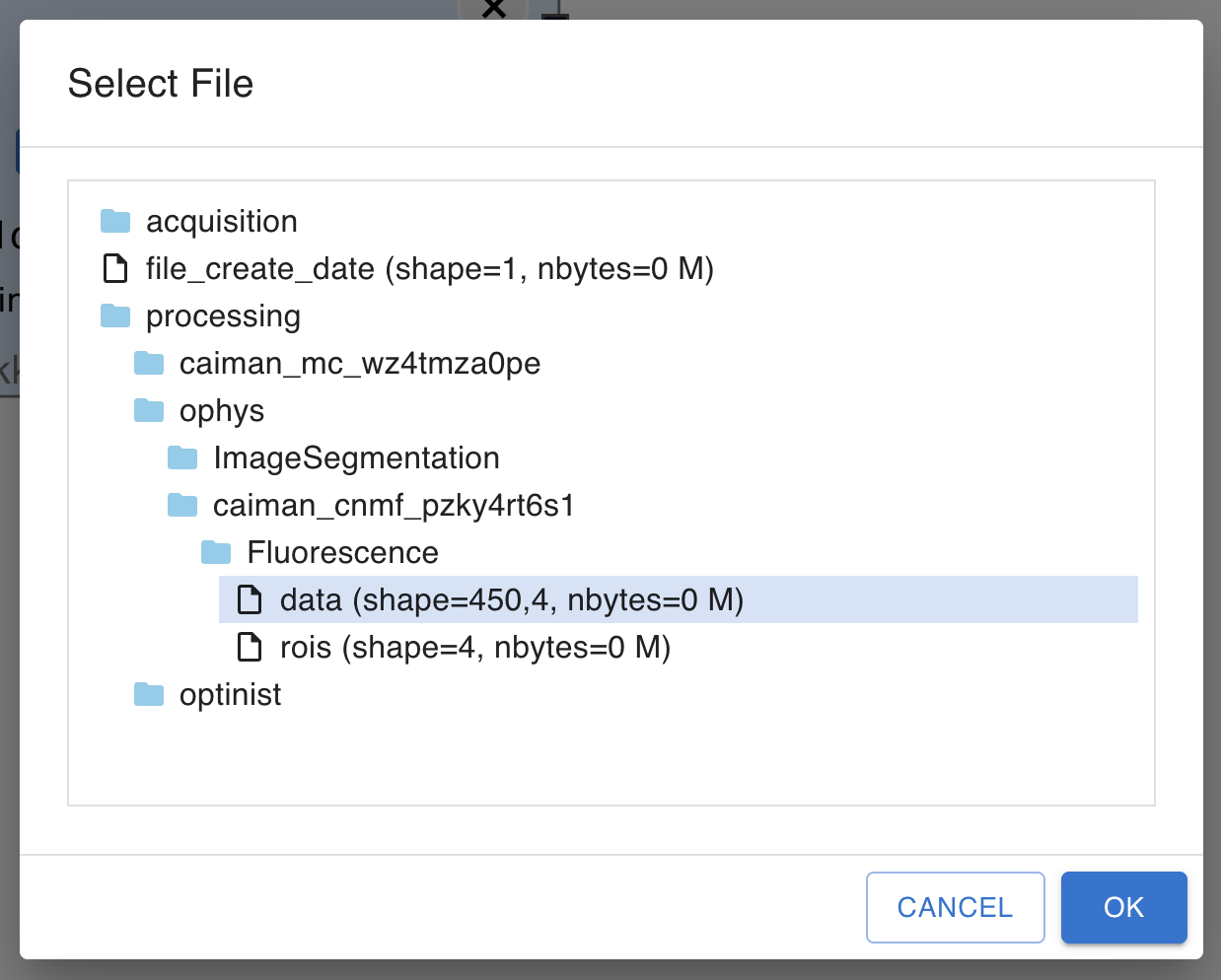
Once a file is selected, you can search through the data structure and select the data to use.
There are some additional utility nodes for processing HDF5 data.
For example, fluo_from_hdf5 extracts fluorescence data from HDF5 data or
roi_fluo_from_hdf5 that extracts roi and fluorescence data from HDF5 data. For more details, refer to the Algorithm Nodes Documentation.
Matlab This node accepts Note CSV, HDF5 and Matlab nodes have black output connectors.
Black output connector can be connected to any input connector.
Be careful; this means that it does not check the format correspondence between input and output. Microscope See Data Nodes for more information Microscope nodes. Currently, the Microscope node can accept following data formats. Inscopix(.isxd) NIKON(.nd2) Olympus(.oir)
Data Nodes
Algorithm Nodes
Create a Workflow
Adding Nodes
Input Data with Data Nodes
input directory under OPTINIST_DIR.
To add files to the directory, see Directory Settings section.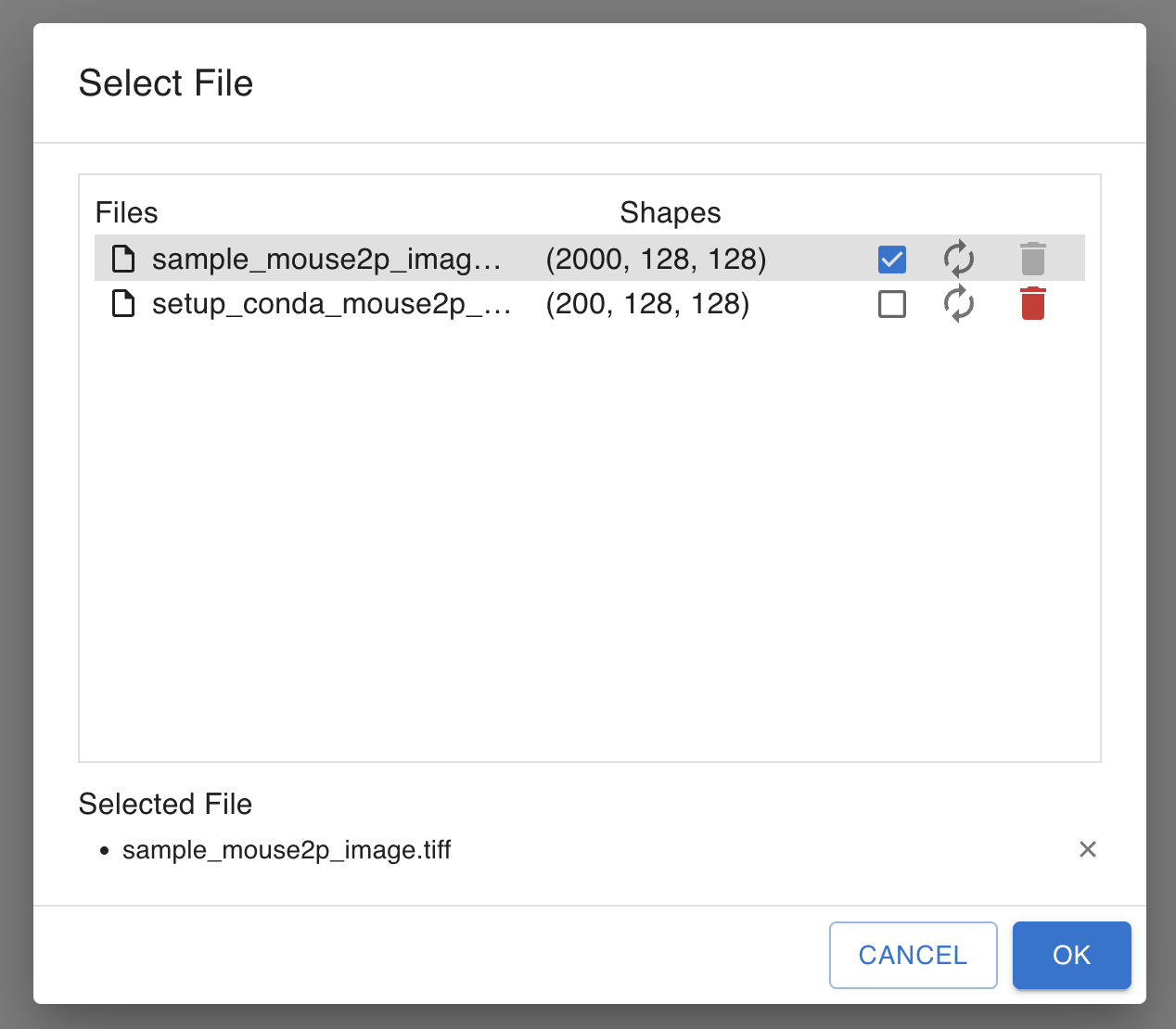
.hdf5 and .nwb file types. NWB is compatible with the HDF5 data format. You can use you OptiNiSt data analysis results, which save in NWB format, as the input.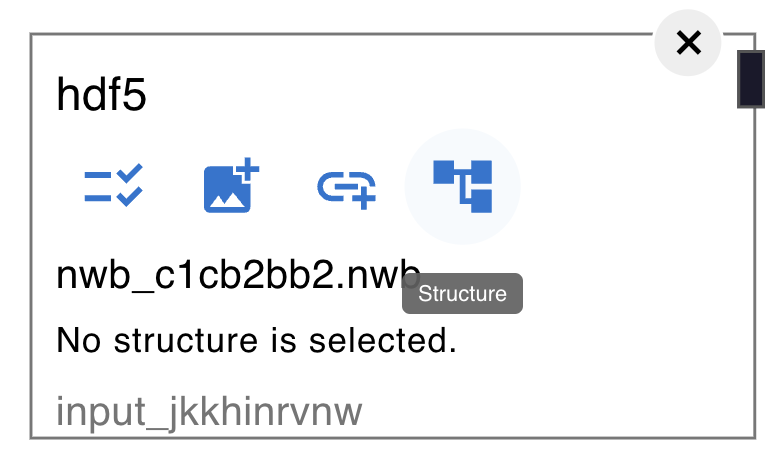
.mat files.
Once a file is selected, you can search through the data structure and select the data to use.
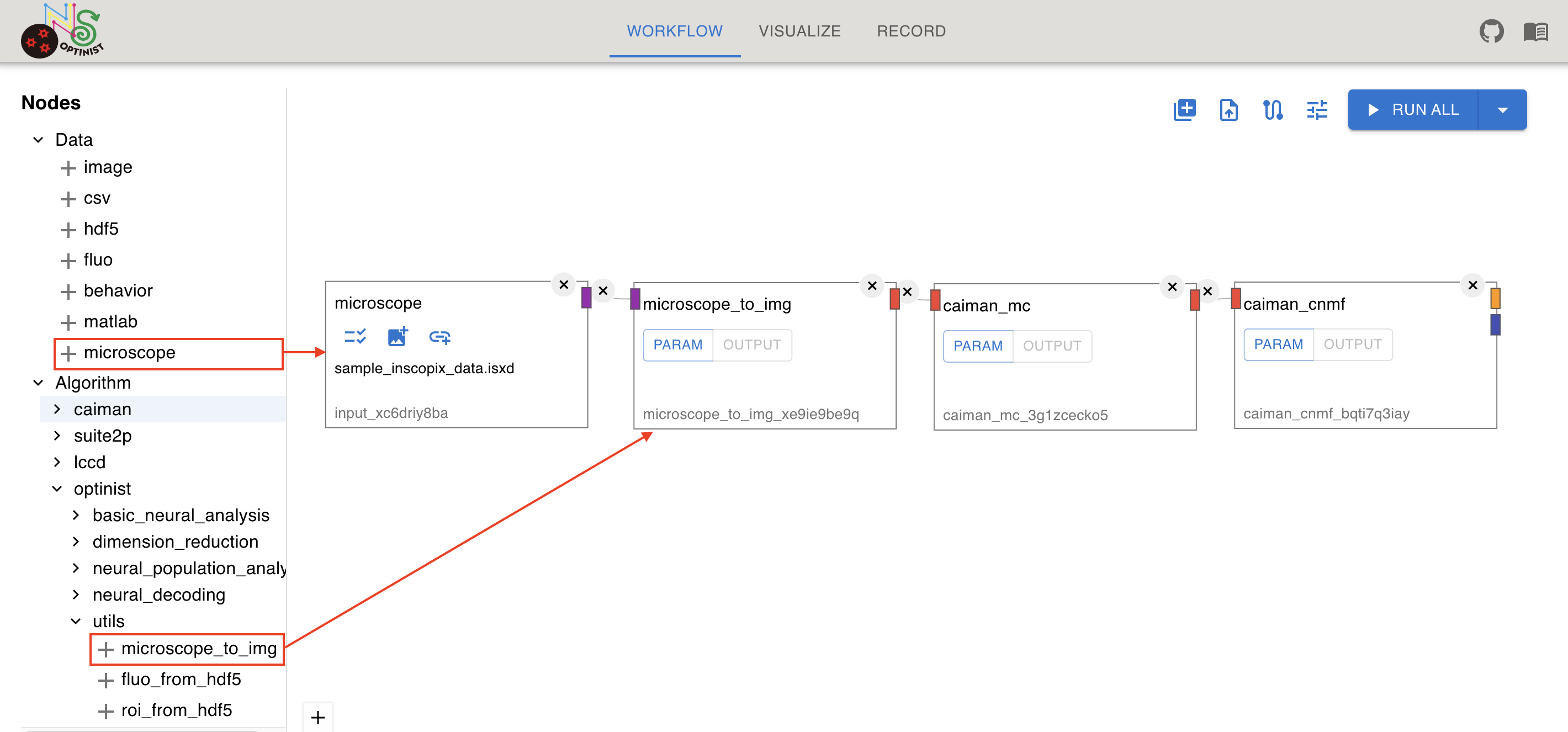
You can convert these data into ImageData so that you can use them in the pipeline. To convert, connect microscope_to_img Algorithm node to the microscope data node.
Algorithm Node Settings
Each algorithm node has PARAM button and OUTPUT button.
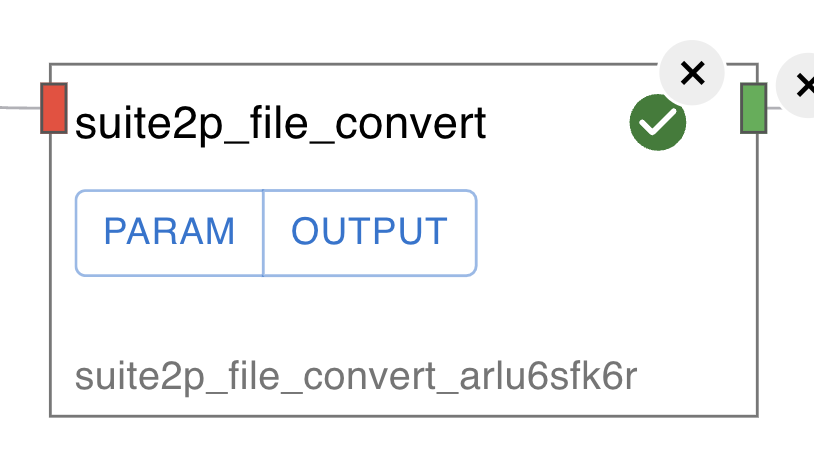
PARAM
You can see or edit parameters for the algorithm. Clicking
PARAMbutton, the parameters are displayed in the right side of the window. More information on each parameter can be found by clicking the external link icon which links to our Algorithm Specifications page.
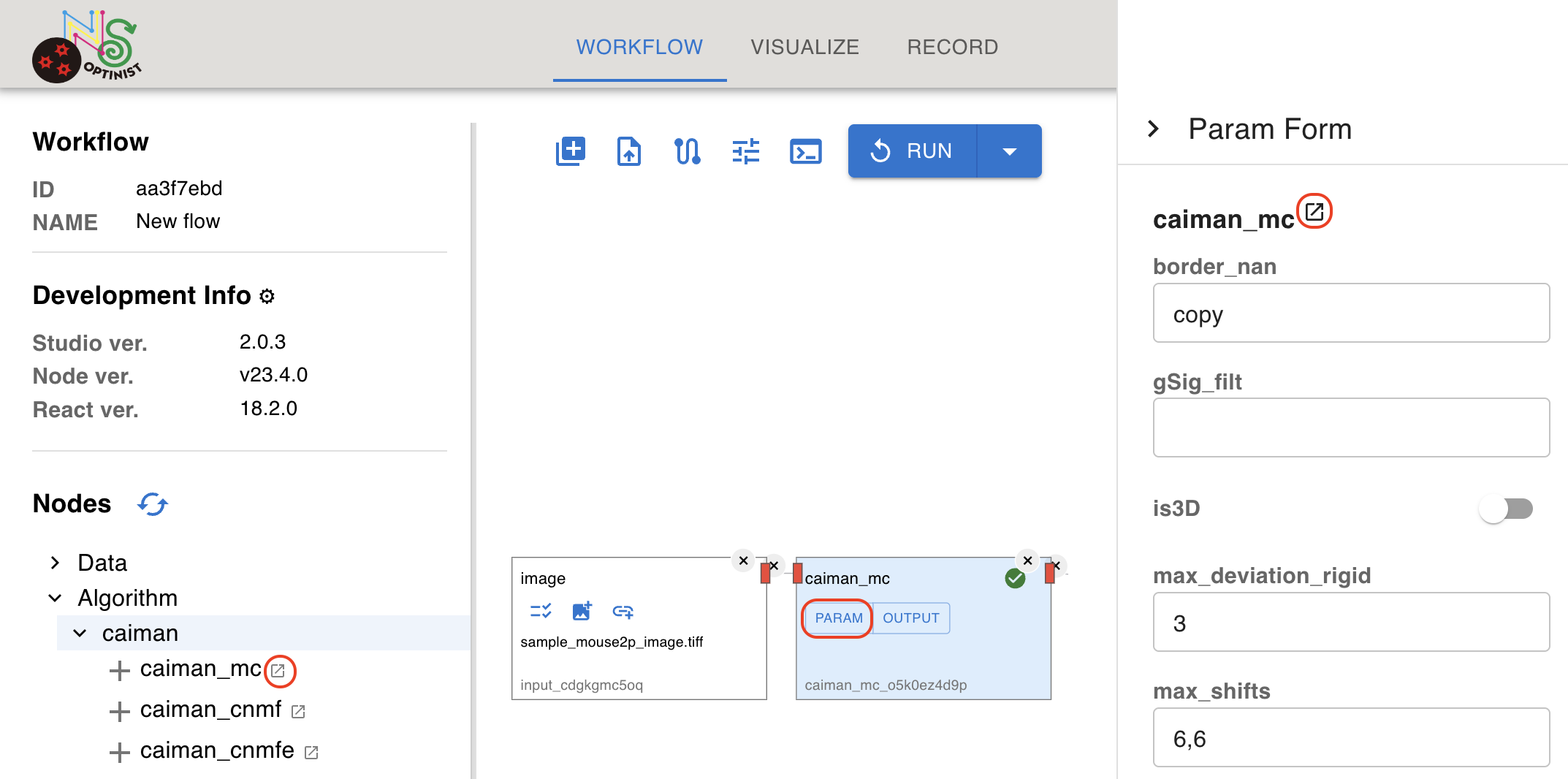
The names, types, and default values of the parameters are the same as the original algorithms. Refer to the original documentation to confirm the meaning of the parameters. The link list is available at Implemented Analysis.
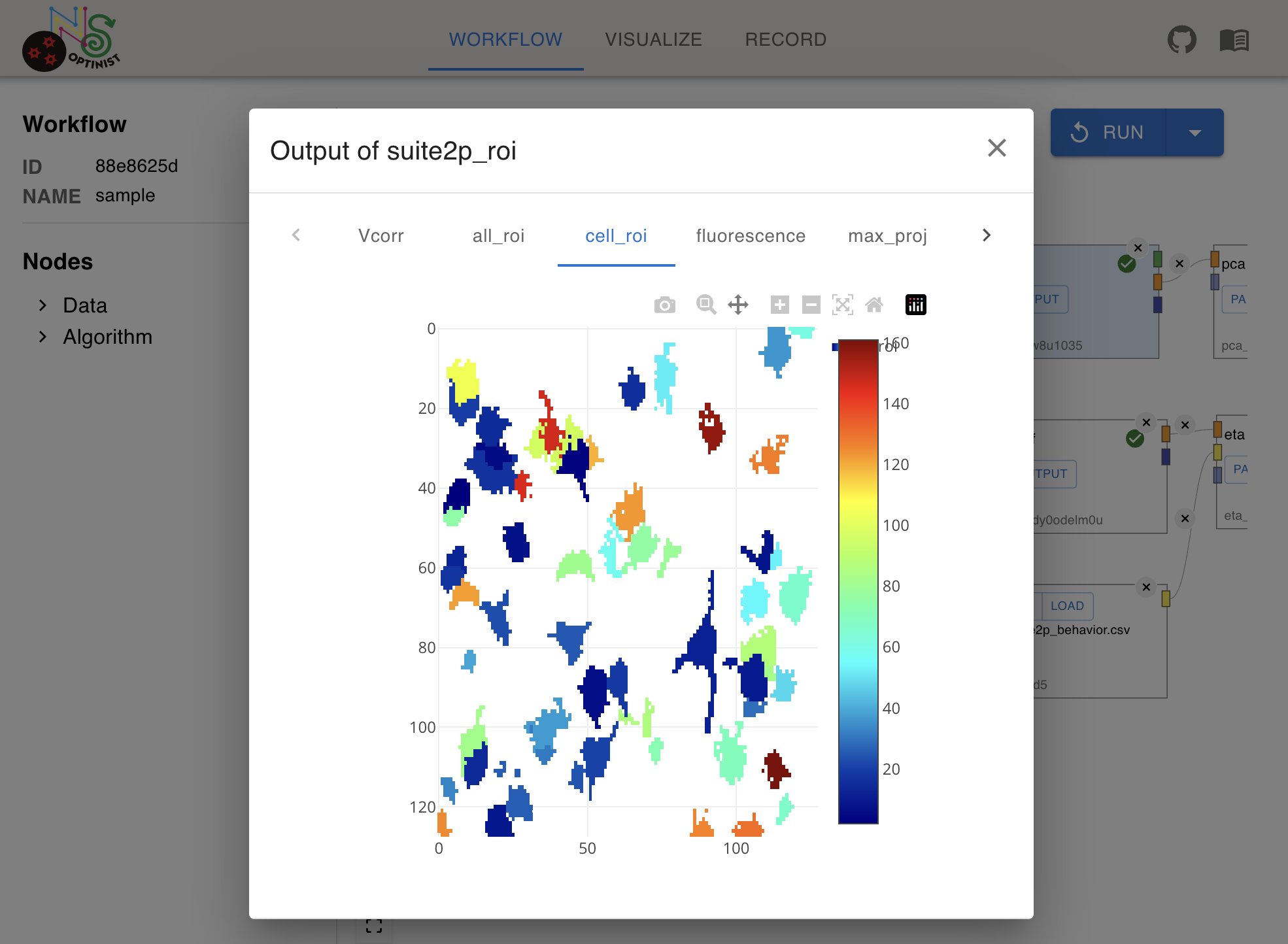
OUTPUT
You can check the results of algorithm quickly after the successful execution of the pipeline. For details about the charts, see Visualize.
Connecting Nodes
Connect colored connectors of the nodes by dragging your cursor from the output connector(right side of the nodes) to the next input connector(left side of the nodes) to create connecting edges.
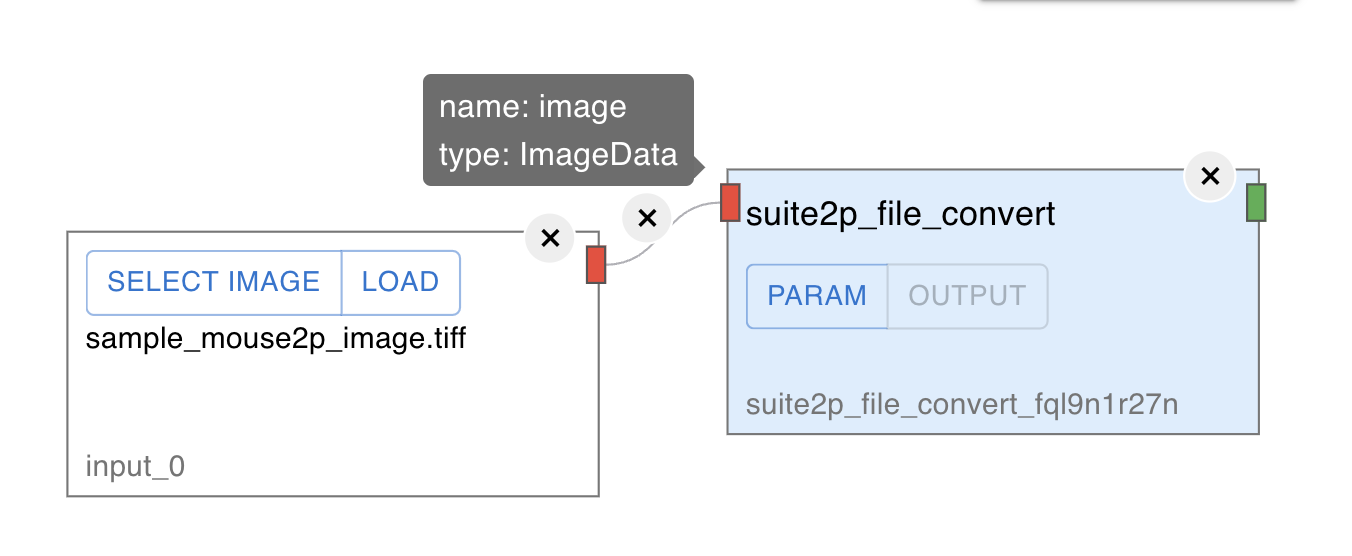
The color of the connector indicates the data type of the input and the output. You can only connect the input and output connectors of the same color.
DataType List
ImageData
Suite2pData
Fluorescence
Behavior
Iscell
Unspecified
Removing Nodes or Connects
Clicking on the x mark on a node or on an edge removes it from the workflow field.
Import existing workflow by yaml file
You can create same workflow by importing workflow config yaml format file. This feature is useful to share workflow template.
Workflow config file can be downloaded from RECORD tab’s executed workflow.
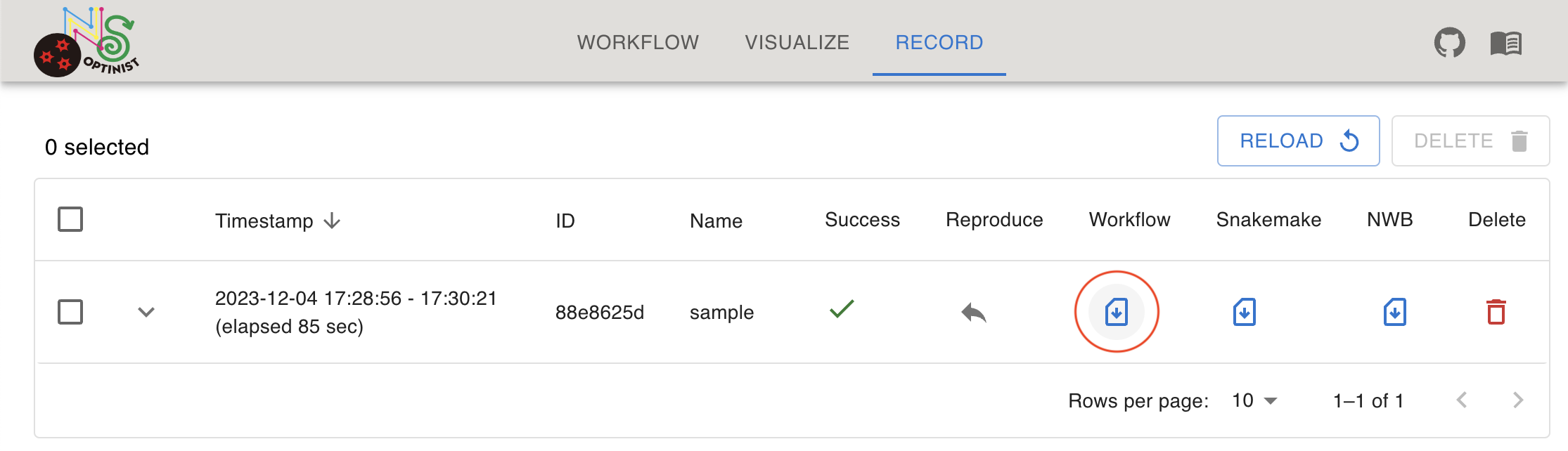
Clicking the import icon button and select shared workflow config yaml. Then you can create same workflow as the file’s record. Input file selection will not reproduced because it may not be in your device.
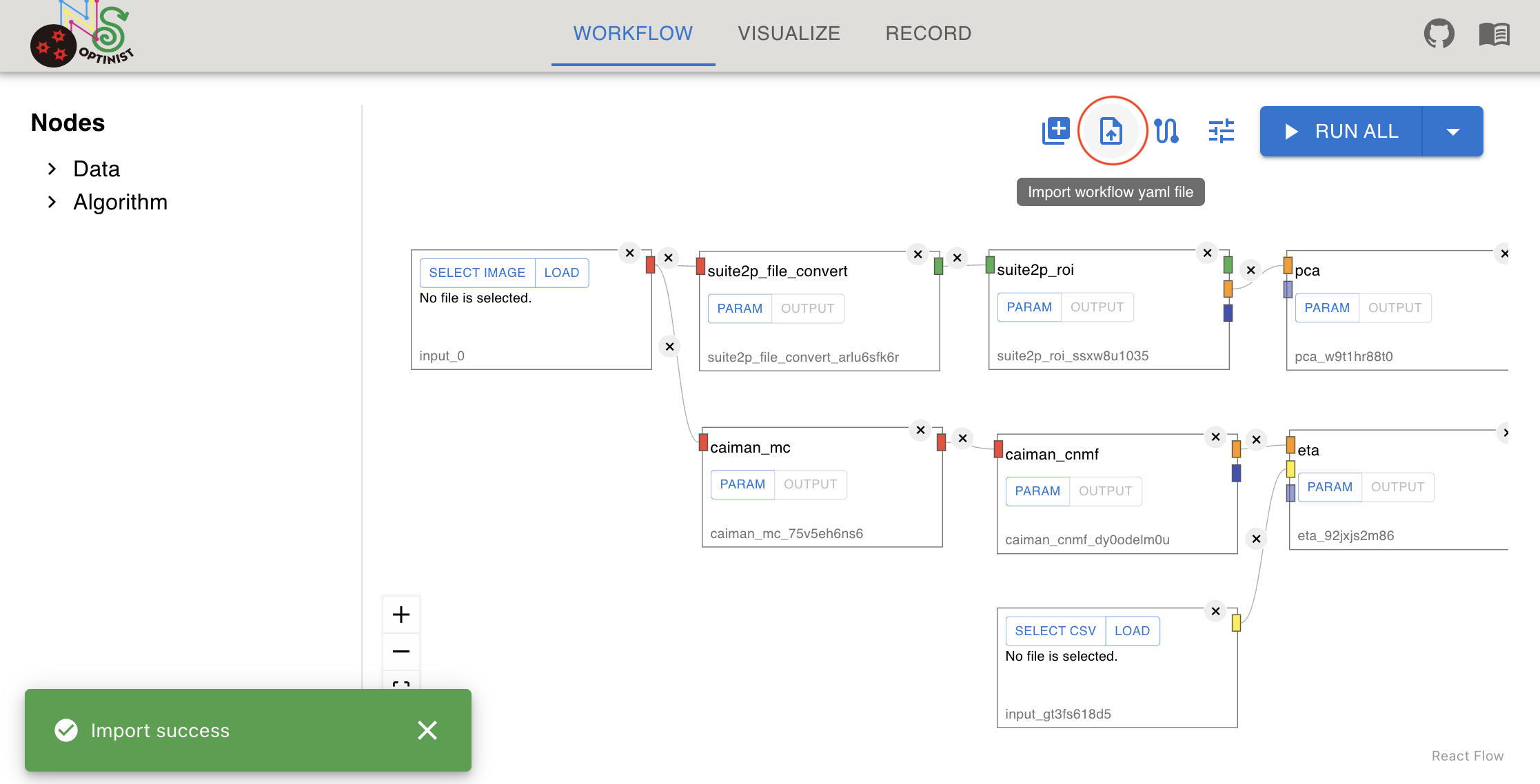
Running Pipelines
Click the RUN button at the top right.
Note that while the workflow running, you cannot
There are 2 types of execution. You can select the type by clicking the dropdown button.
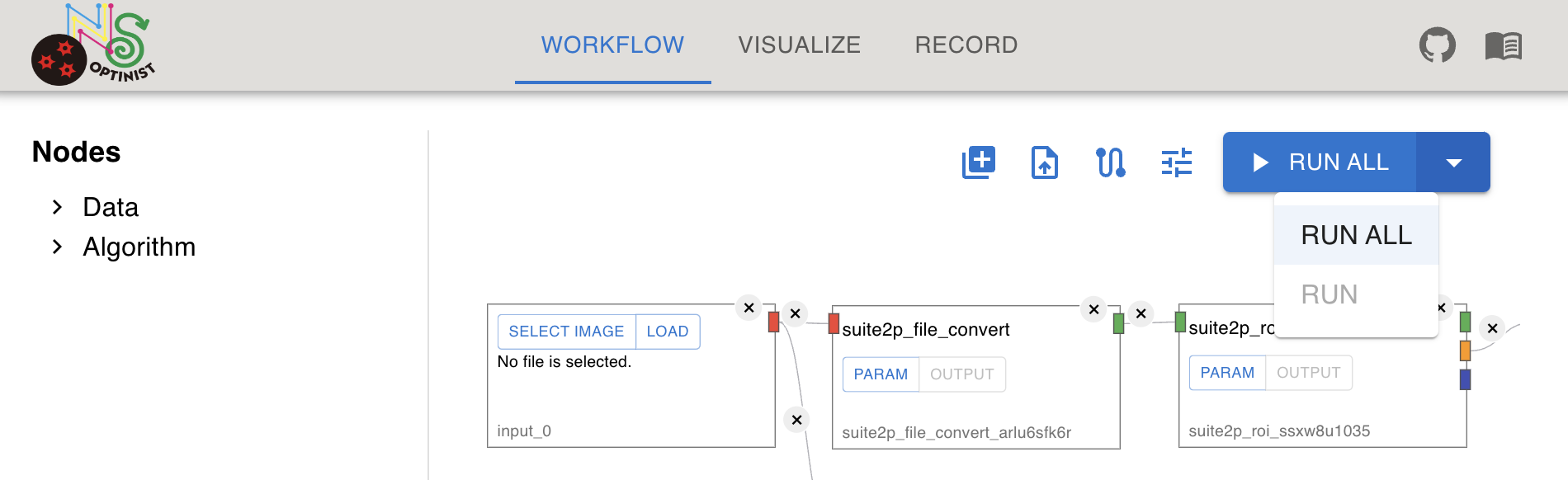
RUN ALL
Runs the entire process.
Assigns a new folder for saving the results. This folder name is only for the user’s convenience. The actual folder name is long digit random letter+number.
RUN
Available only when the pipeline has been executed.
Useful to re-run the workflow with different parameters.
By checking parameter changes and addition of new nodes, it would skip already executed processes.
e.g. Let’s say you have executed following workflow.
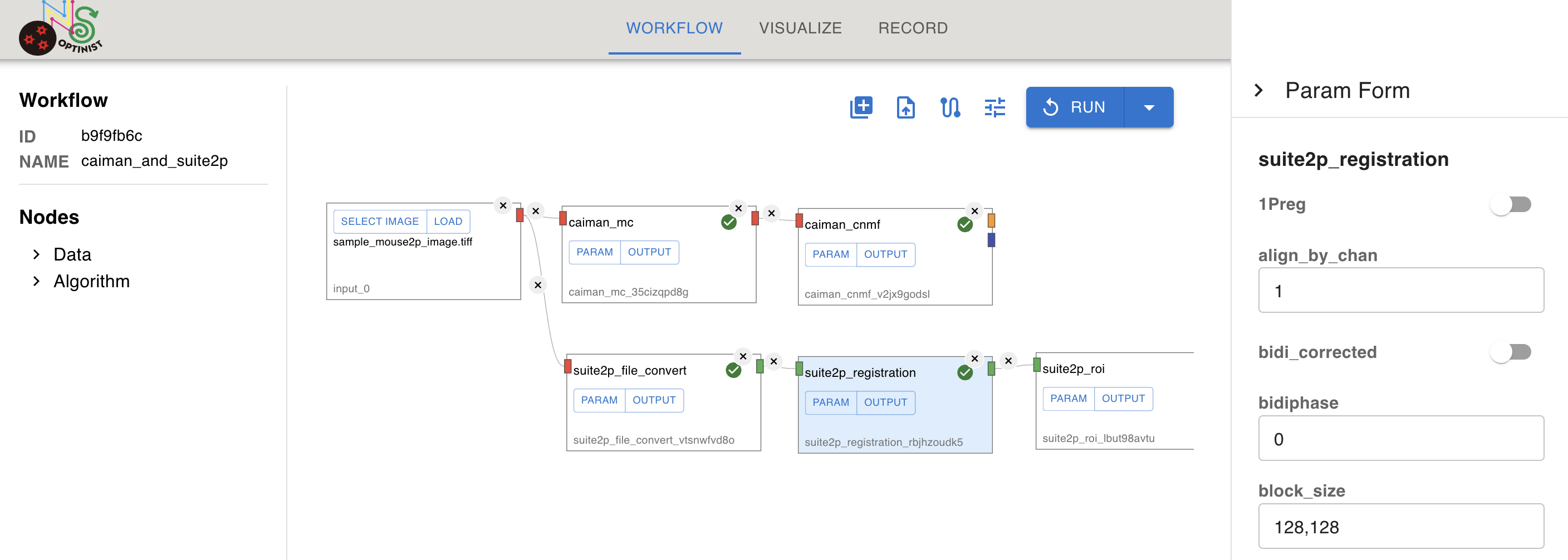
Then you have changed the parameter “block_size” of suite2p_registration from 128,128 to 256,256. With “RUN”, only following nodes would be executed again.
suite2p_registration: because you have changed parameter for this node
suite2p_roi: because its upstream data (from suite2p_registration) would be changed.
Nodes which would be executed by “RUN” are highlighted in yellow.
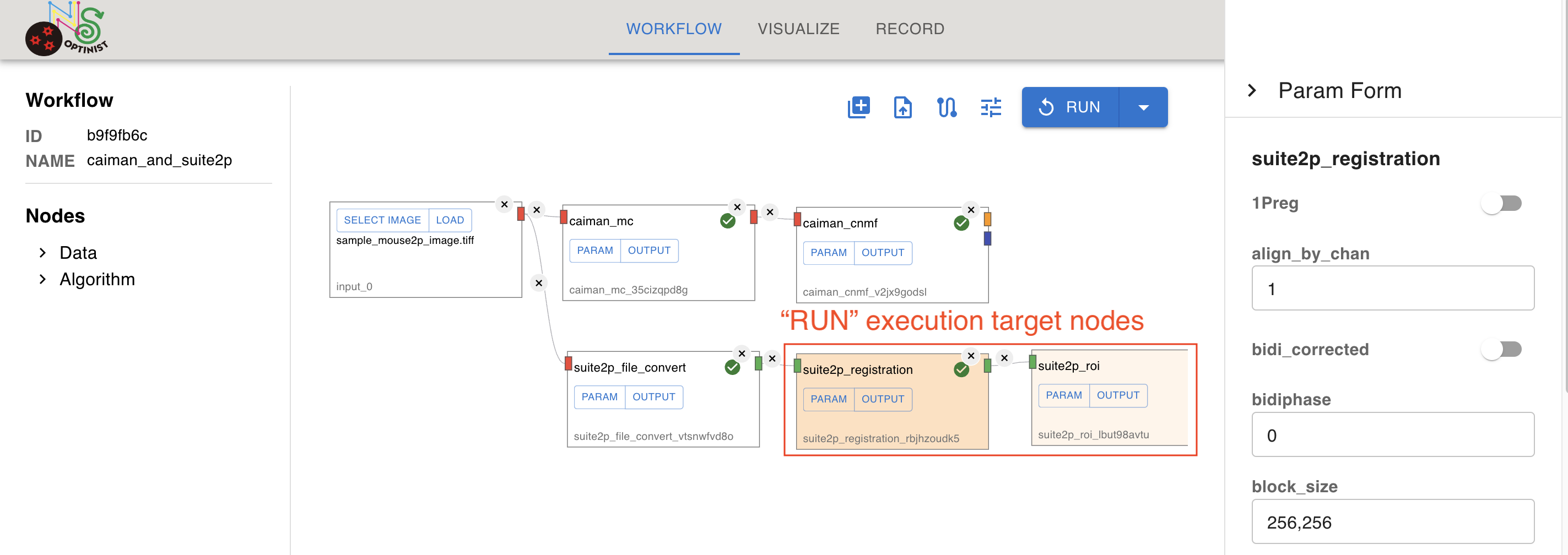
Following changes would affect whole workflow. So you cannot use “RUN” button after changing them.
Input data
NWB settings
Caution
With RUN, results will be overwritten. To avoid this, use RUN ALL.
Note
If you want to set up the Conda Environment for each node first, check Setup Conda Environment
Filtering Data
Overview
Filtering data is only available after executing the pipeline. This feature is particularly useful when you need to examine a specific range of the Region of Interest (ROI) or fluorescence time series.
Step-by-Step Instructions
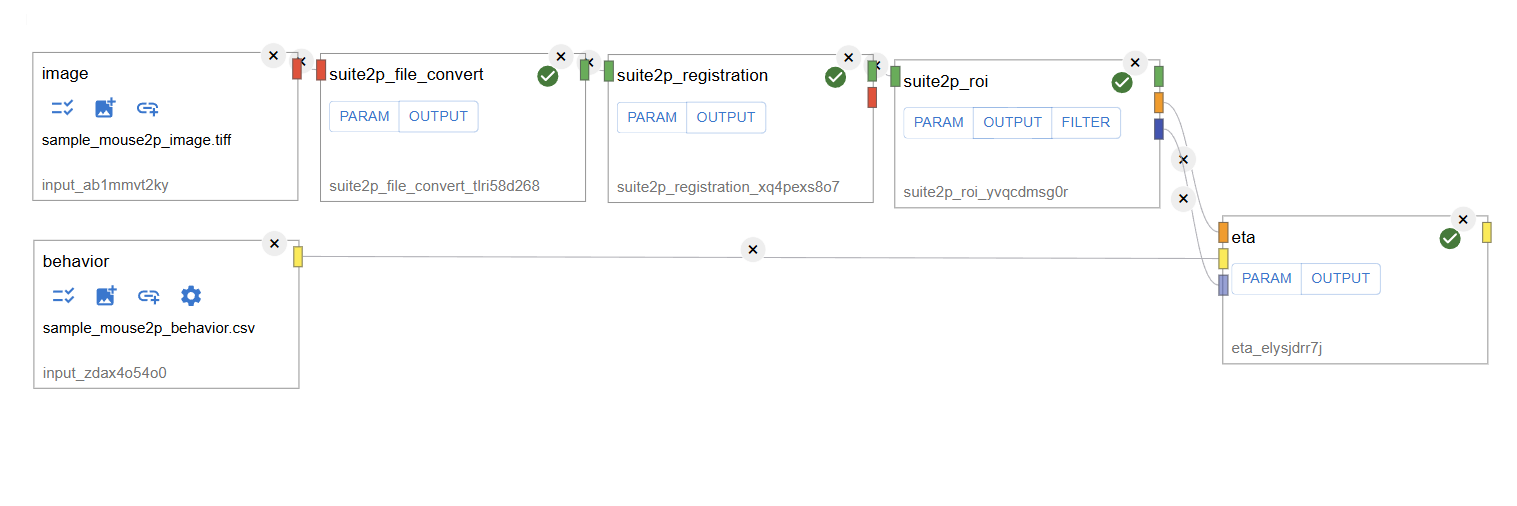
1. Ensure Pipeline Execution
Before applying filters, make sure that you have executed the workflow. For example, if you followed Tutorial 1, your workflow might look like this:
2. Selecting the Filter Option
The filter placeholder values tell you the accepted range, based on the current data. Values can be added as comma-seaparated single integers or as a range, for example: 0, 1, 4:10.
If you want to filter ROI data within a specific range (e.g., 0 to 100), follow these steps:
Locate the
suite2p_roinode in your workflow.Click on the Filter button in the
suite2p_roinode.
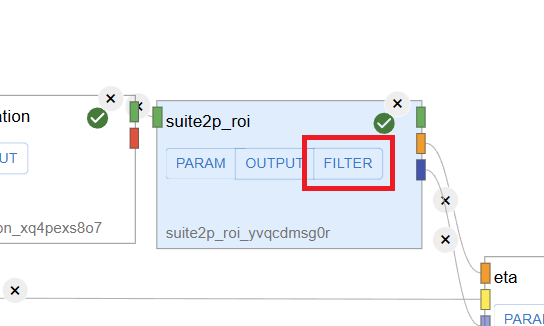
3. Applying the Filter
In the filter settings, set the ROI Data Range from 0 to 100.
Click the Apply button to confirm the filter settings.
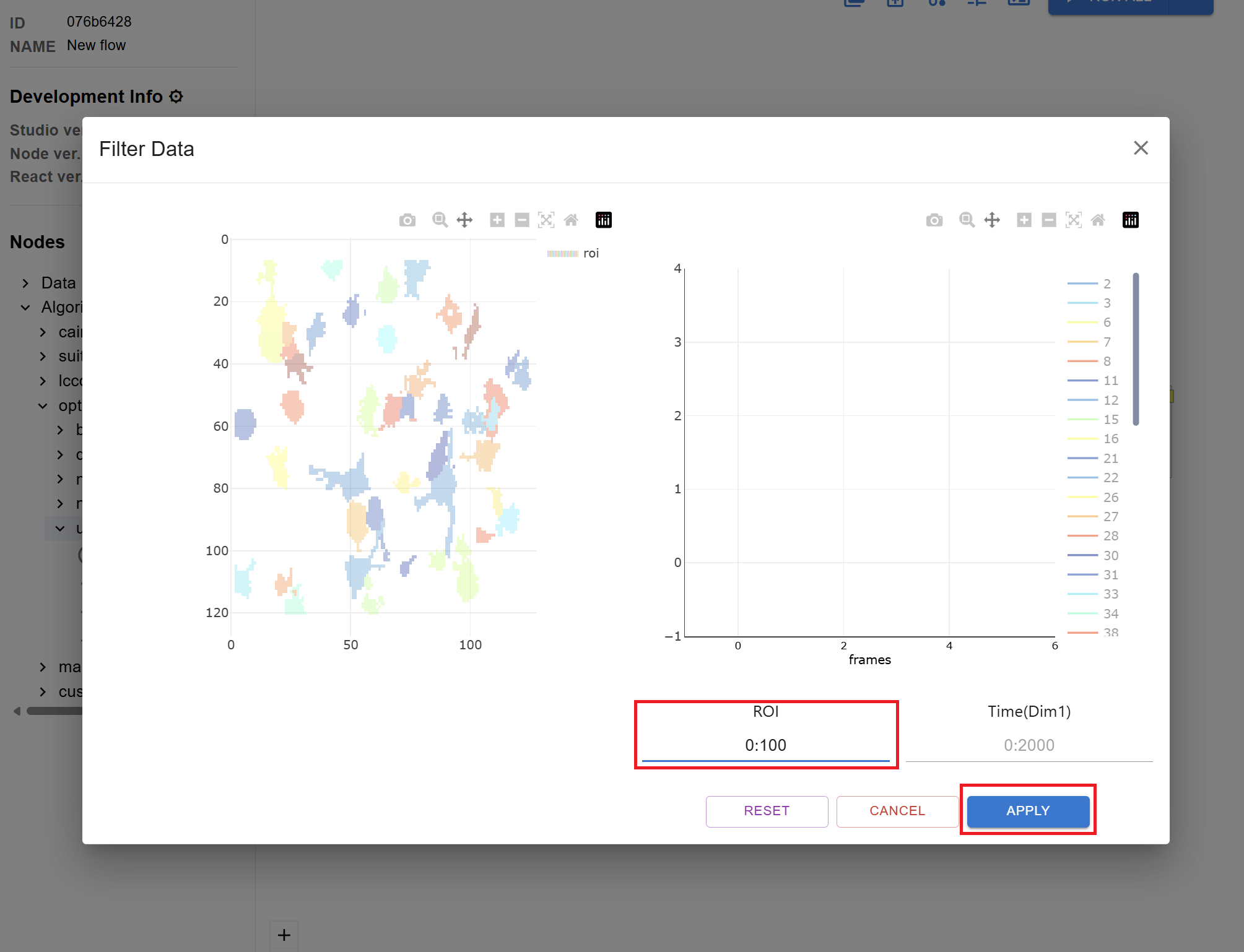
4. Running the Workflow
Once you apply the filter you must RUN in order for the filter to be applied downstream.
The
suite2p_roinode will start loading.When loading completes, the
etanode will be highlighted in yellow.Click the RUN button to execute the workflow and apply the filter changes.
5. Filter output
Filtered data will be saved to the output NWB file once RUN has been performed. Filtered data will be saved in the same folders as the ROI detection algorithm, and additionally filter parameters will be saved in the optinist directory of the NWB. For example for CaImAn:
ophys
ImageSegmentation
filtered_caiman_cnmf_xxxx (id…iscell)
caiman_cnmf_xxxx (id…iscell)
filtered_caiman_cnmf_xxxx
Fluorescence (data, rois, …)
caiman_cnmf_xxxx
Fluorescence (data, rois, …)
optinist
filtered_caiman_cnmf_xxxx_filter_roi_ind
filtered_caiman_cnmf_xxxx_filter_time_ind
Directory Settings
OptiNiSt uses OPTINIST_DIR for retrieving data and saving results. OptiNiSt searches for input data in the ‘input’ directory within OPTINIST_DIR. The default OPTINIST_DIR is /tmp/studio on your computer.
Choosing a folder makes all the TIFF files in the shown sequence an input set of continuous frames.
You may not want to modify your original data folder, or you may want to make your data folder visible and accessible to OptiNiSt because imaging data can be large and take time to copy. You can take either strategy in assigning your data path:
Upload from GUI
Click on the image icon on the node. The LOAD button copies the selected file to your
OPTINIST_DIR/input.
By this method, you cannot upload multiple files or folder at once.
If you want to upload multiple files or folder at once, use the next method.
Copy Files to
OPTINIST_DIRCopy your raw data to
OPTINIST_DIR/input/1/by your OS’s file manager or command lines.Warning
Be sure to copy under
input/1/.1is the default workspace id for standalone mode. If you copy underinput/directly, the file cannot be found from GUI.You can copy folder into the input directory.
If you put folder, you can see the folder from GUI, SELECT IMAGE dialog like this.
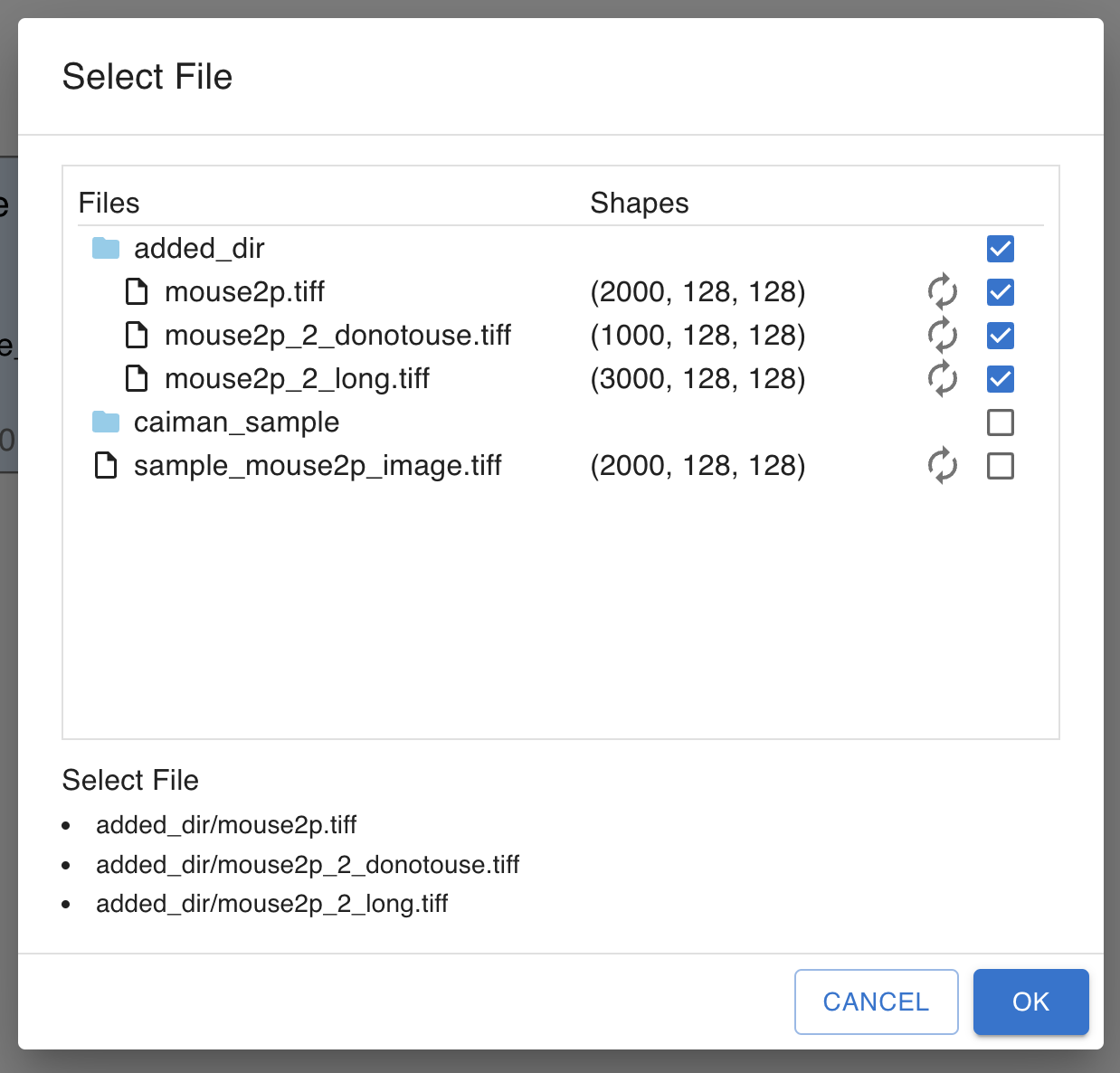
Get file via URL
Click on the link icon on the node.
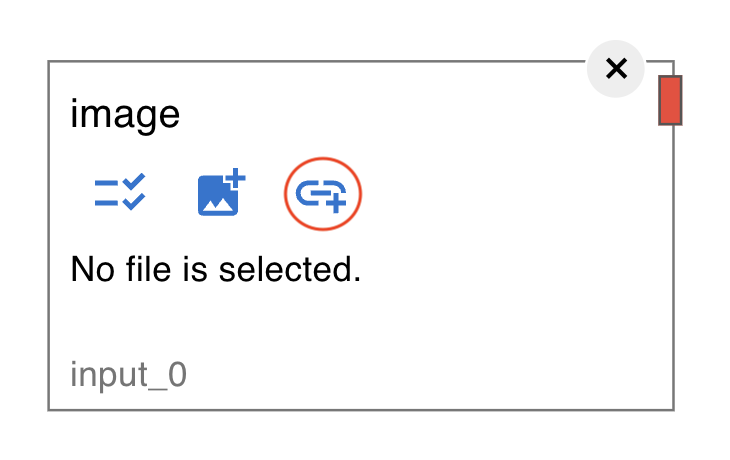
Then input dialog will be shown. You can input the URL of the file you want to use.

Note
The URL should be direct link to the one file. It should be
started with
http://orhttps://.ended with the file name with extension.
And more, download links require authentication are not supported.
Change the Setting of
OPTINIST_DIRThis requires modifying source codes. See Native Platforms (Developer) installation guide section.
OPTINIST_DIRis defined inoptinist/studio/app/dir_path.py. Change line forOPTINIST_DIR,INPUT_DIR, andOUTPUT_DIRaccording to your demand. Changingdir_path.pymay also be necessary when running the pipeline on your cluster computers. Also, you can quickly changeOPTINIST_DIRby changing the environment variable before launching. The change is effective after relaunching.
SNAKEMAKE Settings
OptiNiSt’s pipeline construction is based on Snakemake, a pipeline controlling tool for Python scripts.
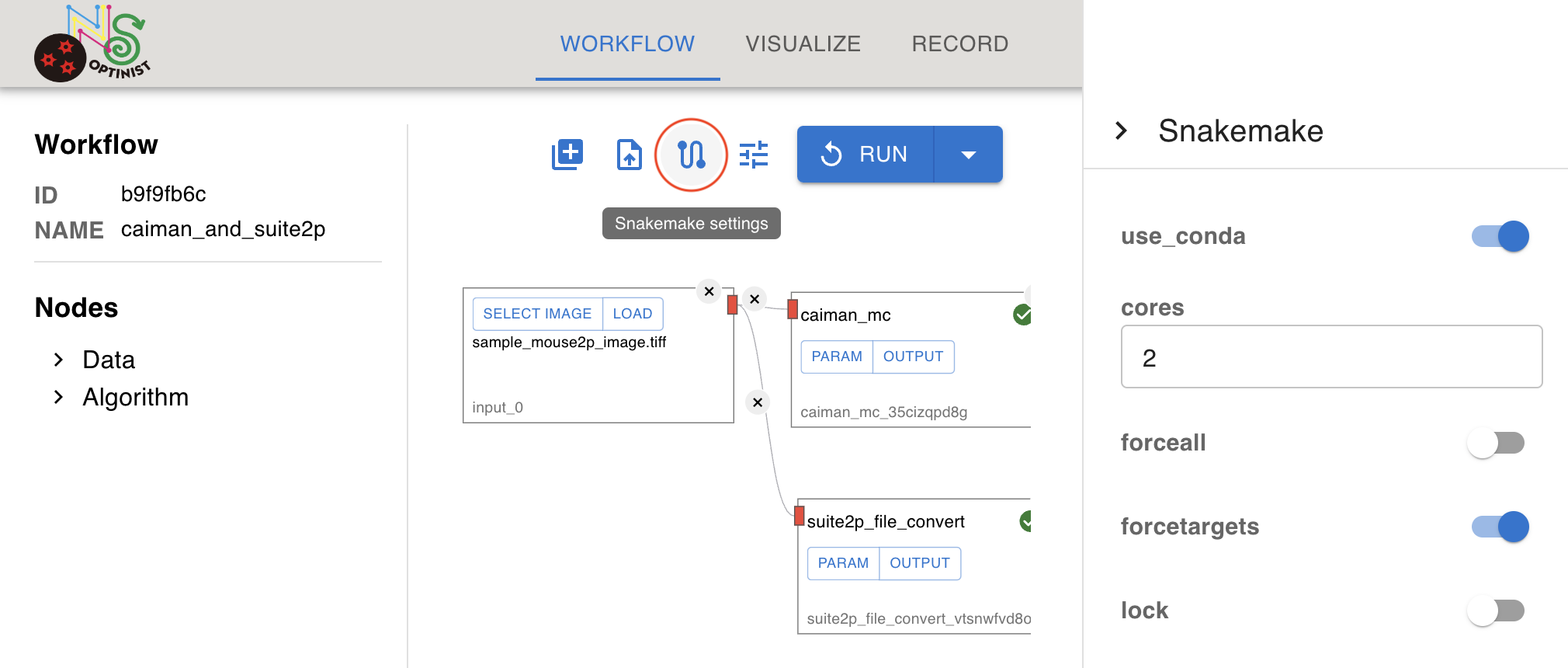
The Snakemake parameter setting is following.
use_conda: If this is on, snakemake uses conda environment.
cores: Specifies the number of cores to use. If not specified, snakemake uses number of available cores in the machine.
forceall: Flag to indicate the execution of the target regardless of already created output.
forcetargets: Users may not want to change this.
lock: Users may not want to change this.
For details about snakemake parameters please refer to snakemake official page.
NWB Settings
Defines the metadata associated with the input data. By configuring this, the output NWB file includes the information set here. You can leave this setting as the default.
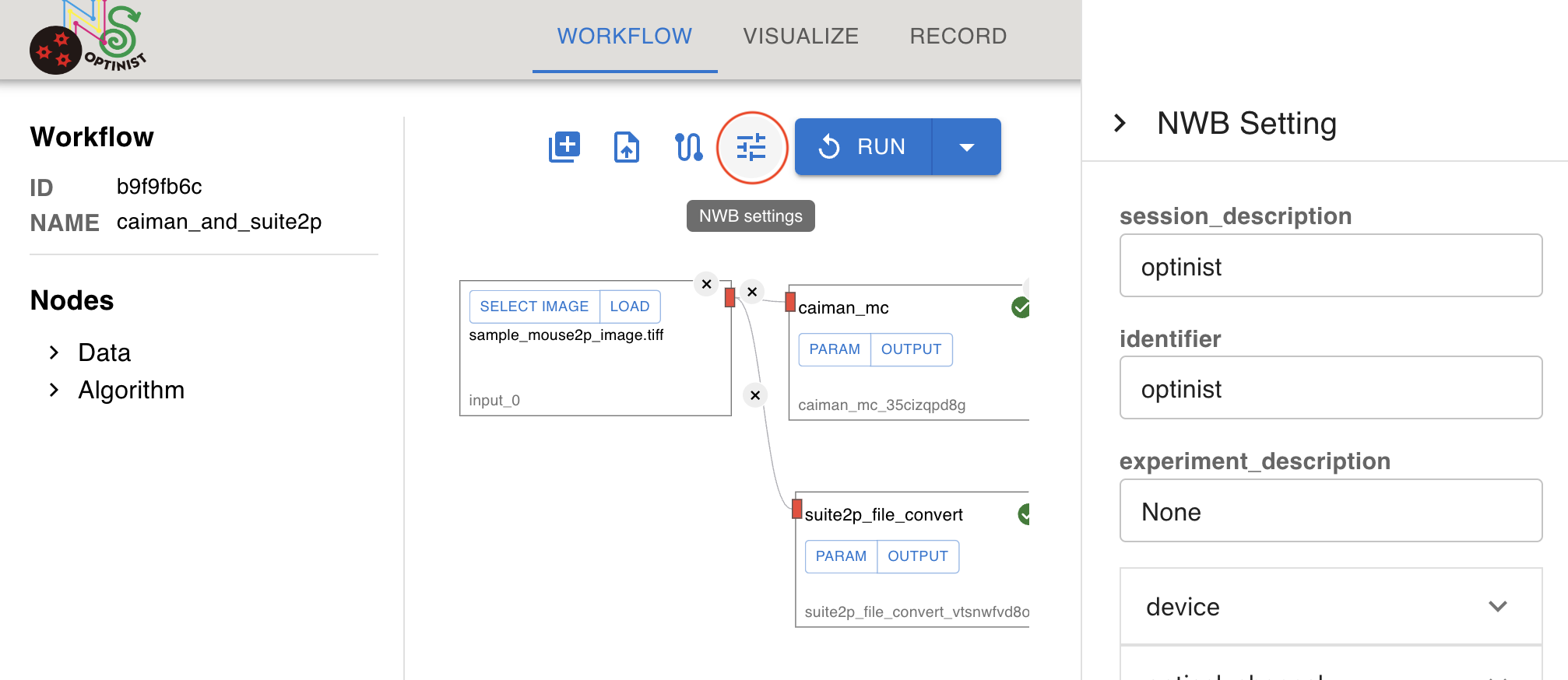
The details of NWB setting in OptiNiSt are following.
session_description: a description of the session where this data was generated
identifier: a unique text identifier for the file
experiment_description: general description of the experiment
device: device used to acquire the data (information such as manufacturer, firmware version, model etc.)
optical_channel: information about the optical channel used to acquire the data
imaging_plane: information about imaging such as sampling rate, excitation wave length, calcium indicator.
image_serises: information about imaing time
ophys: general information about imaging
For general information about NWB, refer to NWB official page.
Note
Basically, these parameters are description for your experiment. So, they are not used for analysis except for following parameters.
imaging_plane.imaging_rateThis will be used as parameter for frame rate. See details in Switch time course plot units.
image_series.save_raw_image_to_nwbIf True, raw image data will be saved to NWB file’s acquisition. If not, only the path to the image data will be saved.
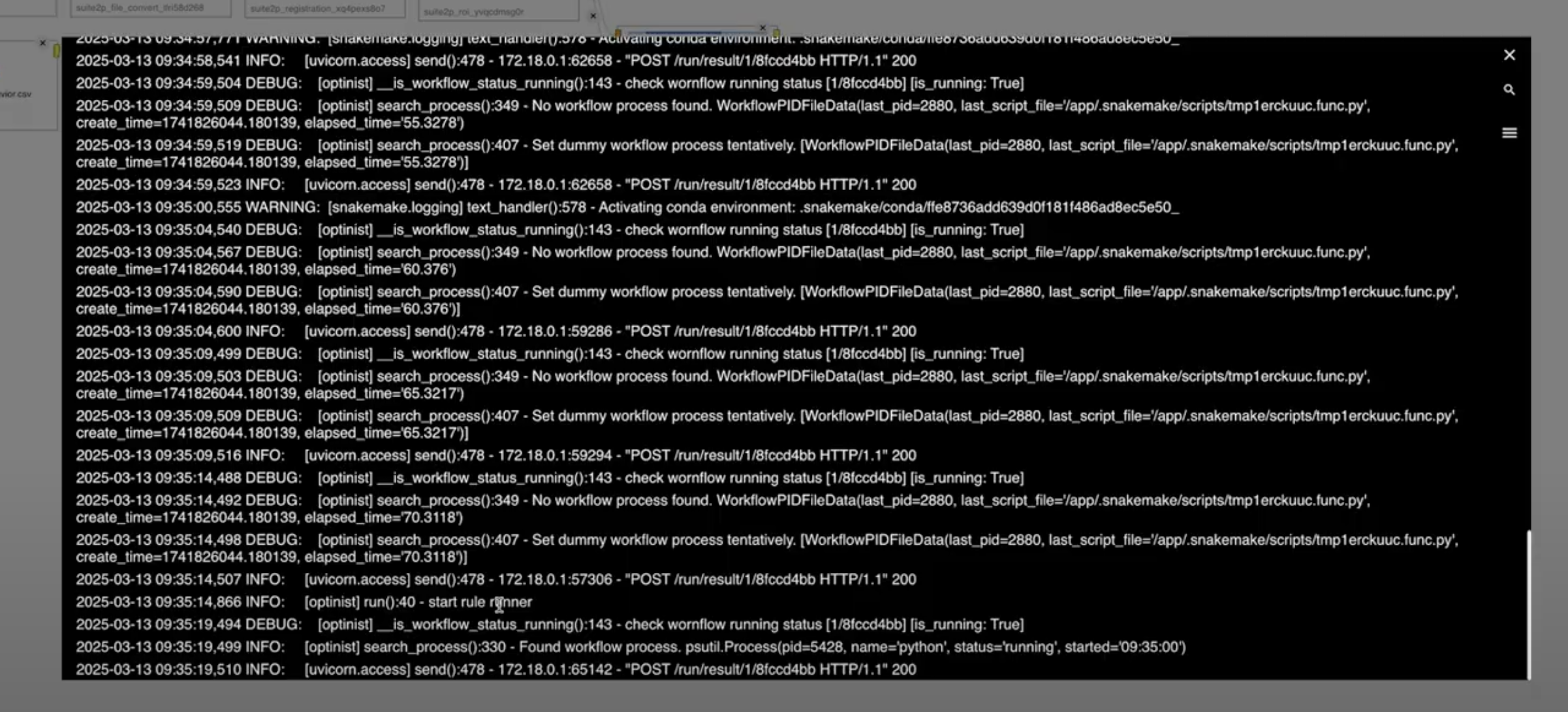
Viewing Logs with Log Viewer
When running a workflow, logs are continuously generated to provide insights into the execution process. These logs can be monitored and analyzed using the Log Viewer.
To access the logs, simply click on the Log Button in the interface.
Key Features of Log Viewer
The Log Viewer provides powerful capabilities for log analysis, including:
Real-time Log Monitoring – View logs as they are generated while the workflow runs.
Highlight & Copy – Easily highlight and copy log entries for further investigation or sharing.
Keyword Search – Search for specific words or phrases to quickly locate relevant log entries.
Log Level Filtering – Filter logs based on their severity level to focus on critical events.
Supported Log Levels
Logs are categorized into different levels based on severity:
Log Level |
Description |
|---|---|
Debug |
Detailed information useful for troubleshooting. |
Info |
General information about the workflow execution. |
Warning |
Potential issues that may not immediately impact execution. |
Error |
Issues that have affected the workflow but are not necessarily fatal. |
Critical |
Severe errors that require immediate attention. |
Example Log Output